

Сравниваем базы данных
Уважаемая редакция! Мне часто приходится сравнивать большие базы данных в MS Excel. Эта работа отнимает много времени и сил. Хотелось бы узнать, какие есть приемы для ее автоматизации? Если можно, опубликуйте такой материал в одном из номеров вашей газеты. Заранее благодарен.
Валентин Матвеев, главный бухгалтер, г. Харьков
Отвечает
Николай КАРПЕНКО, канд. техн. наук, доцент кафедры прикладной математики и информационных технологий Харьковской национальной академии городского хозяйства
С необходимостью сравнивать базы данных рано или поздно сталкивается любой бухгалтер. И это неудивительно. Поиск ошибок в учете, проведение различных сверок, выявление изменений в бухгалтерских реестрах, так или иначе связаны с этой задачей. И что интересно: сама по себе задача предельно понятна. А вот ее решение зачастую является серьезной проблемой. Ведь в реальной жизни бухгалтерские базы могут быть очень большими — тысячи, десятки, даже сотни тысяч записей. Чтобы сравнить их, понадобится масса драгоценного времени. В то же время процесс можно существенно ускорить. И все, что для этого нужно, — освоить несколько несложных приемов сравнения баз данных. О том, как это сделать в программе
Excel, мы поговорим в нашей статье. А начнем с элементарных вещей.
Поэлементное сравнение баз данных
Несмотря на свою простоту, этот вариант часто встречается в практической работе. Итак, наша задача такова. Есть две базы данных. Обе они одинаково отсортированы. Эти базы мы хотим сравнить. И все записи, которые в них отличаются, каким-то образом пометить на рабочем листе. В качестве примера воспользуемся базой, изображенной на рис. 1 (слева). Это фрагмент отчета «
Карточка счета», полученный из программы «1С:Бухгалтерия». В нем часть информации я удалил. Оставил только такие данные: дата операции (колонка «Дата»), название документа (колонка «Документ»), счет дебета проводки (колонка «СчД»), сумма по дебиту (колонка «СуммаД»), счет кредита проводки (колонка «СчК») и сумма кредита проводки (колонка «СуммаК»). Всего таких отчетов у нас два. Они отличаются колонкой «Документ». Наша задача — выявить эти отличия. Делаем так:1) открываем оба документа, через буфер обмена копируем их содержимое на один рабочий лист, как показано на рис. 1;
2) в ячейку «
N3» вводим формулу «=B3=I3». Здесь первый символ «=» — это признак начала формулы. Второй символ «=» — логическая операция. Формула сравнивает ячейки «B3» и «I3». Если они равны, результатом будет значение «ИСТИНА». В противном случае формула вернет значение «ЛОЖЬ»;3) копируем формулу на всю высоту базы данных. Результат показан на рис. 1.
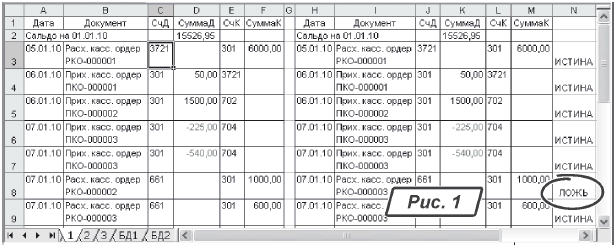
Смотрим на колонку «
N». Некоторые ячейки в ней отмечены значением «ЛОЖЬ». Это и есть те строки, которые отличаются содержимым в колонке «Документ» (столбцы «B» и «I»).Результат мы получили, попробуем его улучшить. Первыми делом откажемся от комментариев «
ИСТИНА» и «ЛОЖЬ». В колонке «N» они смотрятся некрасиво. Но это не все. В таблице мы отметим только те строки, у которых в колонках «B» и «I» записаны разные названия документов. Для одинаковых строк никаких комментариев проставлять не будем. Тогда все отличия между базами будут хорошо видны. Просматривая результат сравнения баз данных с большим количеством одинаковых строк, мы ничего не пропустим. Для решения задачи нам придется изменить формулу для сравнения. Делаем так:1) становимся на ячейку «
N3». Вместо формулы «=B3=I3» пишем выражение: «=ЕСЛИ(B3=I3;«»;«Нет»)»;2) копируем его на всю высоту таблицы. Теперь справа от строк, которые отличаются колонкой «
Документ», появится надпись «Нет» (рис. 2). 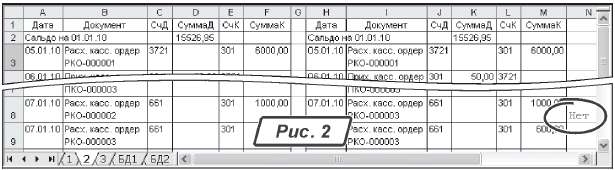
Описанным способом можно сравнить и несколько списков. Для этого в формуле придется использовать логические операции. Например, функцию «И()». Эта функция может содержать несколько параметров, каждый из которых должен быть логическим выражением. Когда все параметры имеют значение «ИСТИНА», функция «И()» тоже вернет значение «ИСТИНА». Если хотя бы один параметр равен «ЛОЖЬ», результат работы функции тоже будет «ЛОЖЬ». В качестве примера я напишу формулу для сравнения трех значений, которые расположены в ячейках «A1», «B1», «C1». Выглядит эта формула так: «=И(A1=B1;B1=C1)». Если все исходные ячейки одинаковые, она вернет значение «ИСТИНА». В противном случае результатом работы формулы будет «ЛОЖЬ». Используя такой принцип, вы сможете сравнить сразу несколько баз данных. И еще. В нашем примере я поместил базы на одном листе с единственной целью — обеспечить наглядность сделанных изменений. На практике вы можете сравнивать данные, расположенные на разных листах рабочей книги. Все, что для этого нужно, — задействовать формулы с трехмерными ссылками.
Сравнение баз данных инструментом «Выделить…»
Иногда работа с формулами при сравнении баз данных нежелательна. В этом случае можно воспользоваться инструментом выделения группы ячеек по условию. Еще раз напомню, что сейчас речь идет о поэлементном сравнении двух списков. Пока мы не рассматриваем вопрос о количестве вхождений элементов из одной базы в другую, о выявлении общих записей в базах данных и т. п. Об этом мы поговорим немного позже. Сейчас нас интересует обычное сравнение списков. Причем выполнить его мы хотим без помощи формул. Делаем так:
1) открываем документ, изображенный на рис. 1. Обратите внимание, что в нем на одном листе собраны две базы данных;
2) удерживая клавишу «
Ctrl», последовательно щелкаем на колонках «B», «I» (выделяем их);3) вызываем меню «
Правка → Перейти…» или нажимаем комбинацию «Ctrl+G». Появится окно «Переход», как на рис. 3; 
4) в этом окне нажимаем кнопку «Выделить…». Откроется окно «Выделение группы ячеек», как на рис. 4;
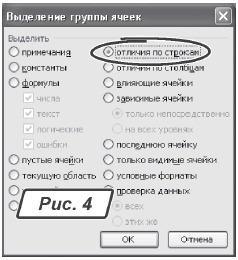
5) в окне для выделения ячеек ставим переключатель «Выделить» в положение «отличия по строкам»;
6) нажимаем «ОК». В колонке «B» Excel выделит блок из нескольких ячеек. Это те названия документов, которые есть в столбце «B», но отсутствуют в колонке «I».
Важно! Результат работы инструмента зависит от последовательности выделения колонок. Если вначале указать столбец «I», а затем щелкнуть на колонке «B», то отличия будут отмечены в колонке «».I
Обратите внимание, что при помощи инструмента «
Выделить…» можно найти не только отличия по строкам, но и по колонкам в нескольких списках.В процессе работы инструмент «
Выделить…» оперирует содержимым ячеек. Это нужно учитывать, когда в данных используются расчетные формулы. Может оказаться, что в разных базах есть два одинаковых значения, но одно из них введено как текст (или число), а другое посчитано по формуле. В этом случае инструмент выделения покажет, что в ячейках находятся разные значения.Совет Прежде чем применить инструмент выделения для сравнения баз данных, преобразуйте все формулы в значения (через меню «Правка → Специальная вставка…»).
Инструмент «Выделить…» удобно использовать совместно с форматированием ячеек. Например, можно сделать так:
1) при помощи инструмента «Выделить…» сравнить две базы данных. Результат Excel выделит в отдельный блок;
2) не снимая выделения, изменить формат этого блока. Например, присвоить им хорошо заметный цвет фона. Теперь все отличия между базами будут видны, как на ладони.
Главный недостаток инструмента «Выделить…» состоит в том, что он не работает с разными листами рабочей книги. Чтобы использовать его для сравнения баз данных, оба списка должны находиться в пределах одного листа.
Сравнение баз данных условным форматированием
Для сравнения баз данных можно обратиться к инструменту условного форматирования. Напомню, что при определении параметров условного форматирования можно использовать не только фиксированный набор значений, но и формулы. Посмотрим, как это применить на практике:
1) открываем базу данных, как на рис. 1. Кстати, списки для сравнения в данном случае могут находиться на разных листах рабочей книги. Просто когда видны оба списка, работа инструмента будет нагляднее;
2) делаем активной ячейку «
B3»;3) вызываем меню «
Формат → Условное форматирование». Появится окно, как на рис. 5; 
4) щелкаем на значке выпадающего списка «Условие 1». Из предложенных вариантов выбираем значение «Формула»;
5) в поле для формулы вводим выражение «=ЕСЛИ($B3=$I3;0;1)»;
6) щелкаем на кнопке «Формат» (рис. 5). Откроется окно форматирования ячеек;
7) в этом окне задаем параметры форматирования. Например, выбираем серый цвет фона;
8) в окне форматирования нажимаем «ОК»;
9) в окне «Условное форматирование» нажимаем «ОК». Мы назначили параметры условного форматирования для ячейки «B3».
Согласно этим параметрам, если содержимое «B3» не совпадет с «I3», то ячейка «B3» будет выделена серым фоном. Используя инструмент «Формат по образцу», параметры условного форматирования для «B3» можно перенести на другие ячейки рабочего листа. При этом адреса в формуле Excel откорректирует автоматически, а именно при копировании формата вниз изменятся адреса строк. При копировании в стороны Excel откорректирует адреса колонок. Именно поэтому в формуле задействована абсолютная адресация ячеек. Теперь делаем так:
1) оставаясь на ячейке «B3», дважды щелкаем на иконке «Формат по образцу» панели инструментов «Форматирование»;
2) удерживая левую кнопку мыши, обводим все ячейки колонки «B», а затем все ячейки колонки «I»;
3) нажимаем клавишу «Ecs» (завершаем работу с инструментом «Формат по образцу»). Результат нашей работы показан на рис. 6. Теперь все несоответствия в базе выделены серым цветом.

Использование условного для сравнения баз данных имеет свои преимущества. Этот способ очень наглядный. Его можно применить сразу к нескольким листам рабочей книги. Кроме того, условное форматирование работает динамически, подобно формулам Excel. При каждом изменении данных сразу же обновляется и форматирование ячеек.
Проверка вхождения элементов одного списка в другой
До сих пор мы сравнивали базы данных поэлементно, когда порядок следования записей в списках был идентичен. На практике зачастую нужно не просто сравнить базы, но и проанализировать вхождение одного списка в другой. Типичный пример — формирование акта сверки, сопоставление данных об оплатах и поступлениях и т. п. Для решения подобных задач есть несколько способов. Все они построены на использовании встроенных функций. Мы рассмотрим два самых распространенных варианта — работу с функциями «
СЧЁТЕСЛИ()» и «ВПР()». И сделаем это на таком примере.Есть две базы данных (два списка), каждая из которых представляет собой реестр из кассовых документов (приходные и расходные ордера). Состав списков показан на рис. 7 и 8. Расположены они на листах с именами «
БД1» и «БД2». Документы в списках следуют в произвольном порядке. Наша задача — сравнить оба списка по полю «Документ». То есть мы хотим выяснить, какие документы из одного списка отсутствуют в другом. 
СПОСОБ 1. Используем функцию «СЧЕТЕСЛИ()»
Идея сравнения в данном случае проста. Для примера начнем с листа «БД1». Мы должны взять каждый элемент этого списка и посчитать, сколько раз он присутствует в базе на листе «БД2». Если для какого-то элемента из базы «БД1» это значение равно нулю, значит, он отсутствует в базе «БД2». Теперь делаем так:
1) открываем документ, как на рис. 7;
2) переходим на лист «БД1»;
3) в ячейку «С1» записываем заголовок «Пр», в ячейку «С2» вводим формулу «=СЧЁТЕСЛИ(БД2!B:B;БД1!B2)»;
4) копируем формулу на всю высоту таблицы. Результат нашей работы показан на рис. 9.
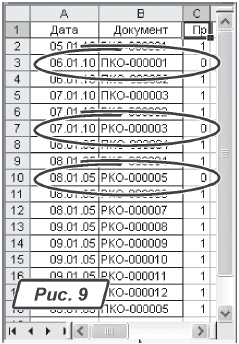
Проанализировав колонку «C» (рис. 9), мы обнаружим, что в базе «БД2» нет документов «ПКО-000001», «РКО-000003», «РКО-000005». Что касается «РКО-000005», тут все понятно. Внимательно просмотрев список «БД2», мы увидим, что такого документа действительно нет в списке. А вот с элементами «ПКО-000001», «РКО-000003» ситуация другая. Эти документы в обеих базах есть. Но в результате преобразования данных в базах «БД1» и «БД2» их названия отличаются. Чтобы увидеть, в чем заключаются эти отличия, делаем так:
1) переходим на лист «БД2»;
2) становимся на ячейку «B3» (элемент «ПКО-000001»);
3) нажимаем на клавишу «F2» (редактирование ячейки) и смотрим на строку формул. В нашем примере в конце текста «ПКО-000001 » стоит лишний пробел. Визуально такое отличие незаметно. Но для функции «=СЧЁТЕСЛИ()» тексты «ПКО000001» и «ПКО000001 » — это разные вещи.
Похожая ситуация возникла и для элемента «РКО000003». Правда, дополнительного пробела в этой строке нет. Зато есть латинская буква «Р»… Нам достаточно просто перепечатать название документа, и Excel найдет элемент «РКО-000003» в базе «БД2». Соответственно в ячейке «C7» появится результат «1».
СПОСОБ 2. Используем функцию «ВПР()»
При сравнении баз данных вместо «СЧЕТЕСЛИ()» часто используют функцию «ВПР()». У нее три параметра: искомое значение «Знач», блок таблицы «Бл», номер результирующего столбца «Ном» и признак интервального просмотра «Приз». Синтаксис функции выглядит так: «ВПР(Знач;Бл;Ном;Приз)». Здесь параметр «Бл» — это таблица с информацией, где производится поиск данных. Параметр «Знач» указывает на элемент, который нужно найти в блоке «Бл». Параметр «Ном» — это номер столбца в таблице «Бл», из которого Excel возьмет результат поиска. Параметр «Приз» определяет способ поиска данных.
Функция «ВПР()» просматривает крайний левый столбец в области «Бл» и пытается найти в нем элемент «Знач». Если поиск успешен, функция возвращает в качестве результата значение из столбца с номером «Ном» области «Бл». В противном случае функция вернет сообщение об ошибке. Обычно в качестве такого сообщения фигурирует значение «#Н/Д» (нет данных).
Если значение интервального просмотра «Приз» равно «ИСТИНА», значения в первом столбце аргумента «Бл» должны быть отсортированы по возрастанию. В противном случае функция «ВПР()» вернет неправильный результат. Чтобы искать данные в неотсортированной таблице, нужно присвоить параметру «Приз» значение «ЛОЖЬ». Аргументами функции «ВПР()» могут быть текстовые строки, числа, ссылки на ячейки с данными для поиска.
Важно! Функция «ВПР()» сравнивает текстовые строки без учета регистра.
Теперь посмотрим, как применить функцию «ВПР()» для решения нашей задачи. Сравним список «БД2» с базой «БД1». Делаем так:
1) открываем документ, переходим на лист «БД2»;
2) в ячейку «C1» вводим заголовок «Пр»;
3) переходим на ячейку «C2», вводим формулу «=ВПР(B2;БД1!B:B;1;0)»;
4) копируем формулу вниз до конца таблицы с базой «БД2». Результат показан на рис. 10. Все элементы базы «БД2», которые отсутствуют в списке «БД1», отмечены текстом «#Н/Д».
Судя по результату (рис. 10), в базе «БД1» нет документов «ПКО000001 », «PКО-000003» и «ПКО-000006». Результат правильный — в названии «ПКО000001 » допущен лишний пробел, «PКО-000003» напечатано с латинской буквой «P», а документа «ПКО-000006» действительно нет в списке «БД1».

Пару слов о работе самой формулы. Для примера выберем ячейку «С2», где записано выражение «=ВПР(B2;БД1!B:B;1;0)». Эта формула просматривает колонку «B» на листе «БД1». В этой колонке она ищет название документа, которое записано в ячейке «B2» базы «БД2».
Таблица для поиска у нас состоит из одной колонки (столбец «B» в базе «БД1»).
Номер результирующего столбца (третий параметр функции «=ВПР()») равен «1». Это означает, что при успешном поиске «ВПР()» вернет в качестве результата название документа из базы «БД1». Чтобы функция «ВПР()» искала значения в неотсортированном списке, я присвоил параметру интервального просмотра значение «0» (или «ЛОЖЬ»). После копирования формулы вниз, таблица для поиска останется прежней — «БД1!B:B» (адреса строк мы не указывали). А вот значение для поиска для каждой строки будет меняться: «B3», «B4», «B5» и т. д. Таким образом, аргументами для поиска у функции «ВПР()» будут все значения колонки «B» из базы «БД2». А искать их она будет в колонке «B» базы «БД1».
В целом с задачей мы справились. Но значения «#Н/Д» в колонке «С», откровенно говоря, раздражают. Попробуем улучшить формулу, применив для этого функцию «ЕНД()». Она относится к группе функций проверки свойств и значений. Ее аргументами могут быть ячейка или формула. Функция проверяет значение аргумента. Если оно равно «#Н/Д», результатом работы «ЕНД()» будет «ИСТИНА». В противном случае функция вернет значение «ЛОЖЬ». Чтобы проверить результат «ЕНД()», можно воспользоваться функцией «ЕСЛИ()». В целом логику работы усовершенствованной формулы можно описать так:
— находим документ функцией «ВПР()»;
— анализируем результат поиска функцией «ЕНД()»;
— если результат «ЕНД()» равен «ЛОЖЬ» (поиск успешен), возвращаем в ячейку пустую строку;
— в противном случае возвращаем в ячейку текст «Нет» (поиск неуспешен).
Осталось реализовать этот алгоритм в виде формулы. Делаем так:
1) ставим указатель активной ячейки на «C2»;
2) вводим формулу «=ЕСЛИ(ЕНД(ВПР(B2;БД1!B:B;1;0))=ЛОЖЬ;«»;«Нет»)»;
3) копируем эту формулу вниз до конца таблицы. Результат нашей работы показан на рис. 11.

Остается применить к таблице автофильтр и отобрать записи, в колонке «Пр» у которых стоит значение «Нет». В результате увидим, что в первом списке отсутствуют документы с номерами «ПКО000001 », «PКО-000003» и «ПКО-000006».
И последнее. Формулы с функциями «СЧЕТЕСЛИ()» и «ВПР()», которые мы применяли для сравнения данных, можно использовать в параметрах условного форматирования. На мой взгляд, это один из самых мощных приемов для проверки баз данных. Особенно на этапе их заполнения.
Удачной работы! Жду ваших вопросов, замечаний и предложений на
bk@id.factor.ua , nictomkar@rambler.ru или на форуме редакции www.bk.factor.ua/forum .


