

Как проверить базу данных
 | Достоверная информация — важнейший элемент в работе любого бухгалтера. Никакой компьютер, никакой самый совершенный инструмент не помогут решить бухгалтерскую задачу, если она изначально опирается на неправильные данные. Поэтому практические приемы поиска и устранения ошибок в базах данных для бухгалтера чрезвычайно актуальны. И от того, насколько разнообразными и эффективными будут эти приемы, во многом зависит успешность всей его работы. Один из таких приемов, направленных на выявление возможных ошибок, я предлагаю рассмотреть этой статье. А точнее, речь в ней пойдет о поиске записей-дубликатов в базе данных. Тех самых записей, которые так часто становятся причиной досадных недоразумений и головной боли при обработке больших объемов информации. Николай КАРПЕНКО, канд. техн. наук, доцент кафедры прикладной математики и информационных технологий Харьковской национальной академии городского хозяйства |
Думаю, что с проблемой поиска дубликатов, так или иначе, сталкивался любой бухгалтер. По крайней мере по моим наблюдениям — это одна из самых распространенных и коварных ошибок в бухгалтерской практике. Поясню подробнее, о чем идет речь. Есть большой реестр (база данных) из нескольких сот, тысяч, а то и десятков тысяч записей. С этим реестром мы собираемся работать в программе Excel. Разумеется, прежде чем что-то делать, данные нужно проверить. Общие цифры нам известны. Поэтому первым делом мы посчитали итоги по реестру, проанализировали, — а они «не идут». При этом есть обоснованное подозрение, что где-то что-то «задвоилось», в реестр попали несколько лишних записей, и они испортили всю картину. Если ошибочная запись одна, а сумма отклонения по итогам нам известна, проблему решить несложно. Для этого можно включить автофильтр, отобрать данные по условию и ошибку, скорее всего, удастся найти. Но на практике такая ситуация встречается редко. По всем известному закону легкое решение обычно невозможно. И сопоставить сумму отклонения с конкретной записью не удастся. В этом случае понадобится применить другой, более общий подход. Суть его очень проста. Нужно внимательно посмотреть на данные, выявить в них те признаки, которые делают каждую запись уникальной, и после этого воспользоваться этими признаками для поиска лишних записей в реестре. Но это, так сказать, общий подход. А нам важнее понять, как он выглядит на практике. Этим мы сейчас и займемся.
Итак, есть база данных, фрагмент которой показан на рис. 1. Эта база представляет собой отчет о продажах, который будет использован для формирования актов сверок по каждому контрагенту. Структура базы, думаю, понятна. Она состоит из семи полей: дата операции (поле «Дата»), номер накладной (поле «Документ»), название предприятия (поле «НаимПредпр»), наименование ТМЦ (поле «Наименование»), дальше идут количество купленного товара (поле «Кол-во»), его цена (поле «Цена») и сумма покупки (поле «Сумма»).
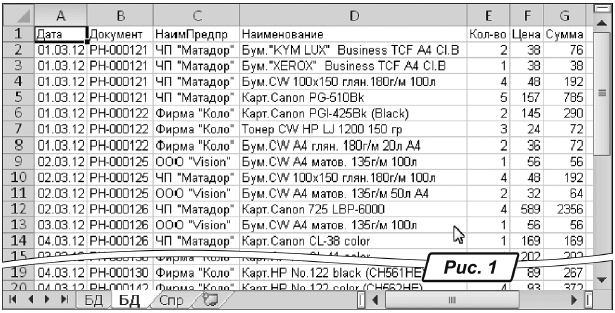
База данных получена из системы автоматизации бухгалтерского учета. А это значит, что итоговые цифры для этого отчета нам известны: по анализу счета мы знаем, что суммарный оборот по базе должен составить 12720,00 грн. В то время как после импортирования данных в MS Excel итог равен 12968,00 грн., т. е. он отличается в большую сторону на 248,00 грн. Отсюда наше подозрение, что в базу каким-то образом попали лишние записи и наша задача — обнаружить их и удалить.
Искать повторяющиеся записи по названию контрагента или по товарам в данном случае бесполезно. Здесь ситуация такова. Посчитать количество повторяющихся записей мы можем при помощи функции «Счетесли()». Но что выбрать в качестве критерия для отбора? Если это будет название предприятия, то таких записей в базе окажется много, и результат мы не получим. Другое дело, если условие усложнить, и посчитать количество повторяющихся строк, где совпадает наименование предприятия и название товара. Вероятность точного совпадения в данном случае будет намного меньше, но все равно она есть. Следуя той же логике, можно к условию отбора добавить еще и поле «Сумма». Записей, где совпадают значения сразу по трем колонкам, в базе данных будет немного. И, вполне возможно, что такой составной критерий сразу приведет нас к решению поставленной задачи. В любом случае, последовательно дополняя критерий новыми условиями, мы всегда сможем сузить область поиска так, чтобы поиск ошибки в базе данных не составил труда. Посмотрим, как это работает на примере таблицы, изображенной на рис. 1. Я предлагаю ограничить критерий для поиска дубликатов тремя значениями: мы будем анализировать название предприятия, наименование товара и сумму продажи. Делаем так.
1. Открываем документ, изображенный на рис. 1.
2. Становимся на ячейку «H1» и вводим заголовок «Ключ».
3. В ячейку «H2» вводим формулу: «=C2&D2&G2». Эта формула объединит данные из колонок «C», «D» и «G» в одну строку.
4. Копируем формулу на всю высоту таблицы. Результат получился неприглядный, но красота нам сейчас ни к чему. Мы будем использовать данные из колонки «Ключ» только для подсчета повторяющихся значений.
5. Становимся на ячейку «I1», пишем произвольный заголовок. В нашем примере я назвал эту колонку «Пр».
6. В ячейку «I2» вводим формулу «=Счётесли(H:H;H2)». Эта формула посчитает количество повторяющихся значений из ячейки «H2» в колонке «H». Таким образом, в столбце «H» мы получим количество записей, в которых совпадает название предприятия, купленный товар и сумма покупки. Если полученное значение равно «2» или больше, то для нас это сигнал о возможной ошибке.
7. Копируем формулу на всю высоту таблицы. Результат нашей работы показан на рис. 2. Посмотрим, что у нас получилось.

8. В меню «Главная» щелкаем на иконке «Сортировка и фильтр» (группа «Редактирование»).
9. Из открывшегося меню выбираем вариант «Фильтр». В заголовках колонок появятся значки для фильтрации данных.
10. Щелкаем левой кнопкой на таком значке в колонке «Пр». Откроется окно настроек, изображенное на рис. 3.
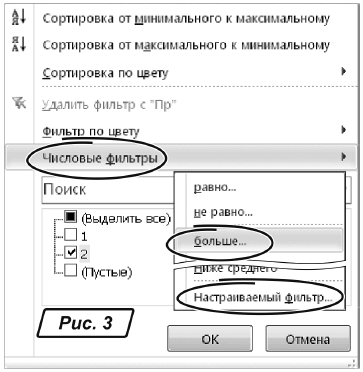
11. В этом окне вводим параметры, как показано на рис. 3, — нас интересуют записи, где число повторов «2» или больше.
12. В окне параметров фильтра нажимаем «ОК». Все, повторяющиеся записи у нас как на ладони (рис. 4).

В результате работы автофильтра на экране осталось четыре записи: это строки с номерами «4», «9», «10» и «13». Это означает, что в исходной базе они повторяются ровно по два раза, о чем свидетельствуют значения в колонке «I». На самом деле мы видим, что в базе данных у записей «4» и «10» (контрагент «ЧП "Матадор"» полностью совпадают значения в колонках «НаимПред», «Наименование» и «Сумма». Та же картина характерна и для записей с номерами «9», «10» (предприятие «ООО "Vision"»).
13. Удаляем лишние строки (в базе нужно оставить только один экземпляр из отобранных записей). Пусть это будут строки с номерами «4» и «9».
14. Отключаем автофильтр и суммируем значения по колонке «Сумма». Теперь результат равен 12720,00 грн., что и требовалось получить.
Вместо автофильтра повторяющиеся значения удобно искать с помощью условного форматирования. В нашем примере это можно сделать так.
1. Открываем таблицу, изображенную на рис. 2, щелкаем на иконке «Сортировка и фильтр» и выбираем вариант «Фильтр» (отключаем работу автофильтра).
2. Становимся на ячейку «I2».
3. Нажимаем клавишу «F2» (или щелкаем левой кнопкой в строке формул).
4. Выделяем текст формулы и копируем его в буфер обмена (комбинация «Ctrl+C»).
5. Нажимаем «Esc» — завершаем работу в строке формул и возвращаемся на рабочий лист.
6. На ленте меню «Главная» находим группу «Стили», щелкаем на иконке «Условное форматирование», из предложенного меню выбираем пункт «Создать правило…» (рис. 5). Откроется окно, как на рис. 6.
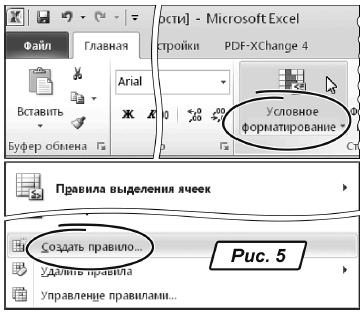

7. В этом окне выбираем вариант «Использовать формулу для определения форматируемых ячеек». Окно примет вид, как на рис. 6, — под строкой «Форматировать значения, для которых следующая формула является истинной:» в нем появится область для ввода формулы.
8. Щелкаем левой кнопкой мышки внутри этой области и нажимаем «Ctrl+V» — вставляем в нее содержимое из буфера обмена. На данный момент в буфере у нас находится текст формулы, скопированный из ячейки «I2».
9. Щелкаем на кнопке «Формат…». Откроется окно «Формат ячеек», изображенное на рис. 7.
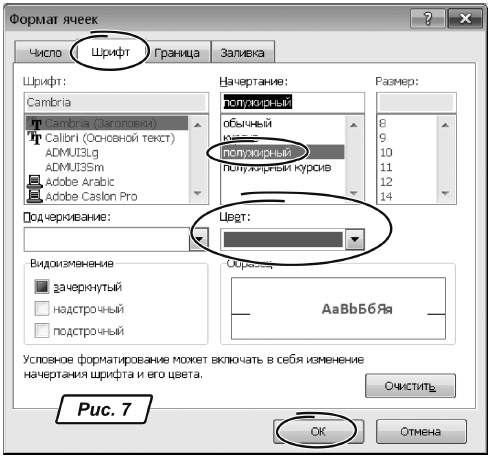
10. В этом окне переходим на закладку «Шрифт», щелкаем на списке «Цвет:» и на палитре выбираем «Красный».
11. Переходим на закладку «Заливка» и параметр «Цвет фона:» устанавливаем в положение «Желтый».
12. В окне «Формат ячеек» нажимаем «ОК».
Условный формат для ячейки «I2» мы создали. Остается распространить его на все ячейки в колонке «I». Делаем так.
1. Становимся на ячейку «I2», где уже заданы параметры условного форматирования.
2. На ленте меню «Главная» в группе «Буфер обмена» щелкаем на иконке «Формат по образцу» (рис. 8).

3. Удерживая левую кнопку мышки, обводим блок значений в колонке «I» для конца таблицы.
Окончательная таблица осталась такой же, как и на рис. 2. Но форматирование колонки «I» в ней изменилось: теперь значения в ячейках «I4», «I9», «I10», «I13» выделены красным шрифтом на желтом фоне. Это означает , что повторяющиеся записи нужно искать среди строк «4», «9», «10» и «13» нашей таблицы.
И еще. На практике бывают ситуации, когда простое объединение значений из нескольких колонок операцией «&» не позволяет получить уникальный рабочий ключ. Сугубо гипотетический пример: объединение значений «Бухгалтер», «&Компьютер», а также «Бухгалтер&», «Компьютер» даст одинаковый результат. В некоторых случаях (хотя это бывает крайне редко!) такую ситуацию нужно отследить и получить разный рабочий ключ. Рецепт в данном случае простой. При объединении формул операцией «&» нужно между значениями вставить произвольный символ. Желательно такой, которого нет исходной таблице. Для нашего примера мы могли бы использовать знак «\». И тогда выражения для рабочего ключа «="Бухгалтер" &"\"& "&Компьютер"» и «="Бухгалтер&" &"\"& "Компьютер"» дадут разный результат. В первом случае получится «Бухгалтер\&Компьютер», а во втором — «Бухгалтер&\Компьютер». И проблема будет решена.
И последний момент. Мы рассмотрели универсальный прием для поиска повторяющихся значений в базе данных. Его можно использовать не только во всех версиях MS Excel, а вообще в любой электронной таблице. Если же говорить о программах Excel 2007(2010), у них есть другие, специальные инструменты для решения нашей задачи. О том, что это за инструменты, каковы их преимущества и недостатки, мы поговорим в одной их наших следующих статей. А на сегодня все.
Успешной работы! Жду ваших писем, предложений и замечаний на bk@id.factor.ua, nictomkar@rambler.ru или на форуме редакции.



