

Как распознать таблицу
Уважаемая редакция! Мне время от времени приходится сканировать и затем распознавать печатные документы. В основном это различные бланки, формы отчетности и т. п. Использую FineReader 8.0. Так как пользуюсь я этой программой недавно, опыта работы с ней мало. Наверное, поэтому часто возникают проблемы при распознавании таблиц, особенно когда текст напечатан мелким шрифтом и оригинал низкого качества (средний ксерокс). Подскажите, как правильно обрабатывать таблицы? Может, найдется несколько советов? Заранее благодарю.
Ю. Савина, г. Харьков
Отвечает
Тамара КРАВЧЕНКО , консультант «Б & К»
Сканирование и распознавание документов — процесс специфический. Это не означает, что он сложный и подвластен только профессионалу. Ничего подобного. Проблема заключается в другом. Бухгалтер привык оперировать текстом, числами, диаграммами. Здесь он чувствует себя как рыба в воде. Но как только речь заходит о распознавании документа, волей-неволей приходится обращаться к элементам компьютерной графики. Для бухгалтера эта среда непривычна, подводные камни ему малознакомы. Из-за этого и возникают досадные ошибки, которые делают процесс распознавания длительным и (что самое обидное!) малоэффективным. Хотя на самом деле все очень просто: нужно выполнить несколько условий — и большинство проблем исчезнут, так и не возникнув. Ведь современные программы распознавания (OCR-программы) обладают отличными алгоритмами решения задачи. Если пользоваться ими умело, то свою работу они выполнят блестяще, при этом неважно, обрабатываете вы текст или таблицу. Поэтому, отвечая на вопрос, мы должны выяснить четыре момента:
— что можно распознавать и чего не стоит;
— на что следует обратить внимание при подготовке документа к распознаванию (в том числе табличного);
— как быстро распознать и откорректировать документ;
— как сохранить документ и передать его в офисную программу.
По этому плану и построим ответ, акцентируя внимание на распознавании основных бухгалтерских объектов — таблиц.
Процесс распознавания…
Подробно о процессе распознавания мы писали в статье «Как распознать… документ» (см. «Б & К», 2008, № 9 — 10), так что повторяться не будем, а напомним только самое главное. Распознавание — это перевод графического файла в формат текстового документа или электронной таблицы. Его используют, чтобы получить электронную версию документа из печатного оригинала. Для выполнения такой работы есть специальные программы, например система оптического распознавания FineReader. Исходным материалом для нее служит отсканированное (сфотографированное) изображение. Программа FineReader анализирует его, пытаясь найти фрагменты со «смысловым» содержанием (текст, таблицы, рисунки). Иными словами, она определяет
структуру документа, выделяет из обезличенного изображения буквы, слова, предложения по их внешнему виду. Затем, опираясь на эту информацию, FineReader формирует текстовый (или табличный) документ, проверяет его по системе словарей и предлагает пользователю для окончательного контроля. Когда проверка завершена, результат работы можно передать в текстовый процессор Word или таблицу Excel, а там уже с документом можно делать все что угодно.Процесс распознавания многошаговый и состоит из таких этапов:
1) сканирование документа (получение его изображения);
2) передача его в программу распознавания (загрузка одного или нескольких изображений);
3) обработка изображения (очистка от мусора, поворот, устранение искажений и т. п.);
4) разметка изображения. Здесь указывают,
как FineReader должен обработать те или иные фрагменты рисунка: что считать таблицей, что интерпретировать как обычный текст и т. д. Это важный этап работы, от которого зависит качество конечного результата;5) распознавание размеченного изображения;
6) просмотр результатов работы, корректировка ошибок распознавания;
7) преобразование результатов в формат Word или Excel.
Посмотрим, как все это сделать на практике.
…и его реализация
в FineReader
В качестве примера сразу берем
табличный документ, например фрагмент налоговой накладной (рис. 1). В этом документе есть все отличительные черты бухгалтерского бланка: сложная шапка, объединение строк и колонок, повернутый текст. Документ получен копированием экрана с помощью комбинации клавиш «Alt+Print Screen».
Важно!
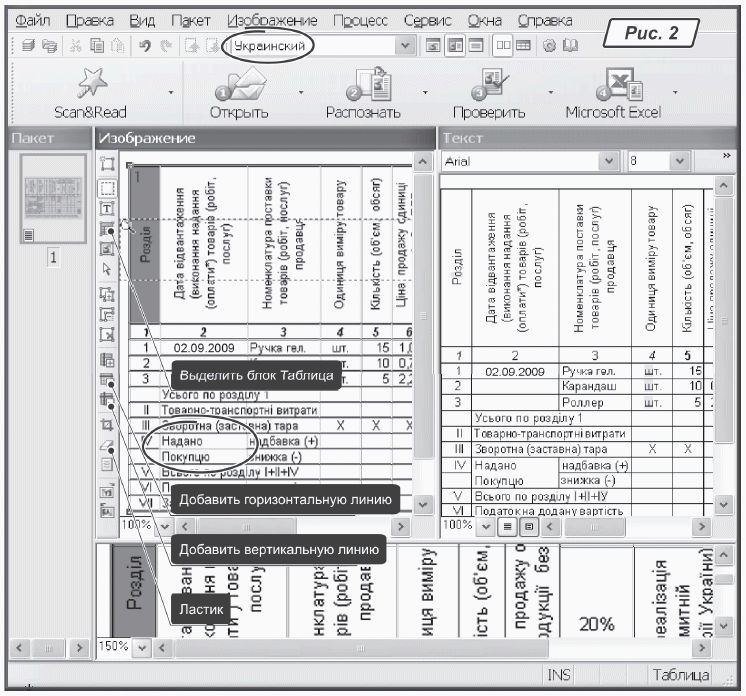
Для хорошего распознавания изображение должно быть разрешением порядка 300 dpi и по размерам соответствовать оригиналу. У нас это условие не выполняется, так как копия экрана имеет разрешение в пределах от 76 до 120 dpi (подробнее о характеристиках изображений рассказано в статье «Бухгалтеру — о графике» («Б & К», 2007, № 10 (16)). На одном из этапов мы откорректируем разрешение прямо в программе FineReader.Вызываем FineReader. Можно воспользоваться ознакомительной версией 8.0, скачав ее с http://www.abbyy.ru/Download/. Появится окно, как на рис. 2 на с. 20. В верхней его части есть пять иконок: «Scan&Read», «Открыть», «Распознать», «Проверить» и «MicroSoft Excel». Они полностью отслеживают вышеописанную последовательность действий по распознаванию документа, не хватает только пунктов по корректировке изображения. Но они есть и находятся в текстовом меню. Основная часть окна разбита на четыре части. Слева расположена область страниц. Каждая страница — это отдельное изображение. Справа от области страниц есть окно «Изображение», в котором виден фрагмент отсканированного документа, а также его разметка. В правой части окна показан результат распознавания — текстовый документ. Его можно править прямо в программе FineReader. Внизу расположена область с увеличенной копией изображения. Между областью страниц и окном «Изображение» есть рабочее меню для разметки рисунка перед его распознаванием. Структура интерфейса, думаю, понятна. Приступим к распознаванию таблицы.
ЗагруЖАЕМ документ
Файл с нашим примером находится на жестком диске. Вначале нужно загрузить его в программу FineReader. Для этого делаем так:
1) нажимаем «
Ctrl+O» или вызываем меню «Файл → Открыть PDF/Изображение»;2) появится окно «
Проводника». В нем находим папку, выделяем нужные файлы, щелкаем на кнопке «Открыть» или нажимаем «Enter». Загруженные изображения появятся в области страниц.Для загрузки документа со сканера служит кнопка «
Scan&Read». Вот как ею пользоваться:1) включаем сканер, кладем в него документ;
2) нажимаем «
Scan&Read». Появится окно управления сканером. Наполнение этого окна зависит от конкретной модели устройства, но в любом случае здесь можно выбрать тип изображения (черно-белое или цветное) и его разрешение;3) определив параметры сканирования, нажимаем «
ОК». Остается только дождаться результата.
коррекТИРуем изображение
Таблица загружена в FineReader. Первым делом нужно выяснить, не нуждается ли графический документ в дополнительной обработке. Такую обработку можно выполнить через меню «
Изображение» (рис. 3 на с. 20). Вот основные возможности данного меню в плане корректировки изображений:
«
Повернуть/Отразить изображение». В этом меню пять пунктов (рис. 4 на с. 21). Их используют, когда страница отсканирована с поворотом и ее нужно переориентировать (текст должен идти в направлении «сверху вниз» и «слева направо»). У нас таблица ориентирована правильно. Раздел «Повернуть/Отразить изображение» пропускаем.
«
Исправить разрешение…». Здесь можно изменить разрешение исходного изображения. Нам такая возможность нужна. Поэтому делаем так:1) нажимаем «
Ctrl+Shift+T» или входим в меню «Изображение → Исправить разрешение…»;2) появится окно, как на рис. 5. Выбираем вариант «
Отсканированное изображение (300 dpi)»;
3) переходим к переключателю «
Исправить разрешение». Он определяет область действия инструмента и принимает одно из двух значений: «Выбранных изображений» или «Всех изображений пакета». У нас загружен единственный рисунок. Поэтому переключатель в группе «Исправить разрешение» можно установить произвольным образом. Оставляем «Выбранных изображений». FineReader изменит разрешение выбранных изображений;4) нажимаем «
ОК».«
Обработать изображение». В этом разделе сосредоточены инструменты для улучшения качества картинки.Важно! Серьезные дефекты изображения FineReader не устранит, но слегка «почистить» его, удалить мелкие погрешности, соринки, пятнышки он сможет.
В меню собраны четыре пункта:
«Устранить искажение строк», «Инвертировать», «Очистить изображение от мусора» и «Очистить блок от мусора». Вот их назначение:—
«Устранить искажение строк» убирает один из распространенных дефектов сканирования, когда некоторые строки текста расположены под углом относительно друг друга. Есть и другие примеры. Например, когда при сканировании книги края строк возле переплета направлены не строго по прямой, а слегка «скруглено» (из-за изгиба листов). Чтобы исправить ситуацию, делаем так:1) выделяем одну или несколько страниц документа;
2) вызываем меню «
Изображение → Обработать изображение → Устранить искажение строк». Строки будут выровнены. Эта операция очень важна при работе с таблицами;Совет Не применяйте выравнивание строк сразу ко всему документу. Обрабатывайте страницы по одной, каждый раз просматривая результат своих действий.
— «
Инвертировать» изменяет цвета и яркость изображения на противоположные;— «
Очистить изображение от мусора» и «Очистить блок от мусора» удаляют с изображения мелкие дефекты (следы пыли, царапины и т. п.).
Размечаем таблицу
Это важнейший этап работы по распознаванию документа. Смысл его такой. Информация в документе бывает трех видов: текст, таблица и рисунок. Программе FineReader нужно точно «знать», с чем она имеет дело. Поэтому на первом же этапе распознавания FineReader делит изображение на участки и пытается выяснить, что в них записано. Для простых документов проблем обычно не возникает, но при обработке страниц со сложным форматированием FineReader может ошибиться. Причем такие ошибки чаше всего возникают при обработке
таблиц.Совет При работе с таблицами, при обработке страниц с версткой в несколько колонок и множеством рисунков размечайте документ вручную.
Овладеть приемами ручной разметки страниц совсем не сложно. Все инструменты для такой работы сосредоточены на специальной панели. Она находится слева от области страниц. Начнем с иконки с буквой «
Т» (это инструмент для определения текстового блока). Ниже идут иконки «Выделить блок Таблица» и «Выделить блок Картинка». Мы собираемся распознавать таблицу. Значит, нам нужно выделить на странице блок типа «Таблица». Делаем так:1) щелкаем левой кнопкой мыши на иконке «
Выделить блок Таблица»;2) ставим указатель на
изображении документа, где начинается таблица;3) удерживая левую кнопку мыши, обводим блок. Делаем это аккуратно.
Лишнее пространство лучше не захватывать, но внешняя граница таблицы должна полностью находиться внутри блока;4) отпускаем кнопку мыши. На документе появилась прямоугольная область синего цвета. Она должна
охватывать фрагмент изображения, который FineReader будет рассматривать как таблицу. Если это не так, изменим размер блока. Для этого выделяем блок и растягиваем его за угол или границу точно так, как вы меняете размер окна в системе Windows. Чтобы удалить блок разметки, выделяем его и нажимаем клавишу «Del».Итак, блок с таблицей выделен. Советую сразу же распознать ее
структуру. Делаем так:1) выделяем блок типа «
Таблица» и щелкаем на нем правой кнопкой мыши;2) из контекстного меню выбираем «
Анализ структуры таблицы». На изображении появится сетка из вертикальных и горизонтальных линий. В идеале эти линии должны лечь точно на границы ячеек исходной таблицы;3) проверяем результат. Наша задача — убедиться, что FineReader правильно распознал все ячейки таблицы. Для этого последовательно щелкаем левой кнопкой мыши по ячейкам табличной части документа. Выделенная ячейка будет окрашена синим цветом. Сверяем ее местоположение с оригиналом. Если при разметке таблицы есть ошибки, их придется исправить вручную.
правим Разметку ТАБЛИцы
Если оригиналы невысокого качества, FineReader может ошибиться уже при выделении блоков в исходном изображении. Такая проблема часто возникает при работе с таблицами. Например, FineReader может пропустить слишком бледную линию границы и объединить несколько ячеек в одну или, наоборот, разделить ячейку там, где этого делать не нужно. В любом случае разметку документа придется откорректировать самому. Для этого на панели разметки блоков предусмотрены специальные кнопки: «
Добавить вертикальную линию», «Добавить горизонтальную линию» и «Удалить линии». Пользоваться ими очень просто:1) щелкните на иконке «
Добавить вертикальную линию».;2) переместите указатель мыши в окно «
Изображение». Вместе с указателем будет перемещаться предполагаемая линия разметки;3) поставьте ее на нужное место, щелкните левой кнопкой мыши. Линия будет зафиксирована, но инструмент продолжает работать! Добавьте остальные недостающие линии в разметке таблицы;
4) выберите инструмент «
Добавить горизонтальную линию». По такой же схеме создайте горизонтальные линии разметки;5) чтобы завершить работу в режиме добавления линий, выберите другой инструмент разметки.
Может оказаться, что при распознавании структуры таблицы FineReader внедрил в документ лишние линии разметки. Чтобы удалить их, сделайте так:
1) щелкните левой кнопкой на инструменте «
Удалить линии» (рис. 2);2) поставьте указатель мыши в область «
Изображение» на линию, которую хотите удалить;3) когда указатель примет форму крестика, щелкните левой кнопкой мыши. Линия исчезнет;
4) чтобы закончить работу с иконкой «
Удалить линии», выберите другой инструмент разметки.В бухгалтерских бланках сплошь и рядом встречаются
объединенные ячейки, причем как по строкам, так и по колонкам. По моим наблюдениям именно в таких случаях FineReader допускает больше всего ошибок. Причины могут быть разные. Например, слишком тонкая бумага оригинала. И сканер, и фотоаппарат — оптические устройства с высокой чувствительностью. При сканировании документа на тонкой бумаге они могут увидеть строки, расположенные с обратной стороны листа. Текст этих строк FineReader не распознает, а вот принять едва различимые тени за бледные линии границ он может, поэтому разметку таблицы сделает неправильно, добавив лишние строки. Чаще всего эта ошибка проявляется на объединенных ячейках, как показано на рис. 6. В оригинале ячейка «Надано Покупцю» в четвертом разделе налоговой накладной объединена на две строки по вертикали. Но FineReader заметил едва заметную горизонтальную тень и разделил ячейку на две строки: в верхней оставил «Надано», а в нижнюю поместил текст «Покупцю». Удаление лишней линии разметки в данном случае не поможет, ведь и справа, и слева от этой ячейки линии должны остаться! Поэтому применим объединение ячеек. Делаем так:
1) выделяем несколько ячеек по вертикали или горизонтали;
2) щелкаем на выделении правой кнопкой мыши. Появится контекстное меню, как на рис. 7;

3) выбираем пункт «
Ячейки таблицы → Объединить ячейки» или вызываем меню «Изображение → Ячейки таблицы → Объединить ячейки».Чтобы
разделить объединенную ячейку по вертикали или по горизонтали сделайте так:1) поставьте указатель внутрь ячейки;
2) щелкните правой кнопкой мыши;
3) из контекстного меню выберите пункт «
Ячейки таблицы → Разбить ячейки».Совет Прежде чем распознавать таблицу, четко определите ее структуру. Если нужно, вручную расставьте линии разметки, объедините и разделите ячейки, причем все это делайте в программе FineReader.
И вот почему. Так или иначе при корректировке распознанного документа вам понадобится сравнивать его с оригиналом. Для этого вам придется в одном окне открыть Word или Excel с документом, в другом — графическое изображение, и затем постоянно переключать окна, сверяя оригинал и результат распознавания. В программе FineReader никаких переключений делать не нужно. И оригинал, и результат распознавания, и увеличенная копия изображения видны в одном окне! Более того, FineReader поддерживает синхронное перемещение указателя по распознанному документу и его графическому изображению. В таком режиме корректировать документ намного удобнее.
СОХРАНЯЕМ РЕЗУЛЬТАТ
Работа по распознаванию большого документа может продолжаться долго. Обидно потратить массу времени на создание блоков и правку документа, а затем все потерять. Конечно, результат нужно периодически сохранять. Для этого в FineReader используется понятие «пакет». Пакет объединяет в себе исходные изображения, их разметку и результат распознавания в том виде, в каком они были на момент его создания. Сохранить пакет можно через меню «
Файл → Сохранить пакет как…». Появится окно Проводника. В нем выбираем папку, вводим название пакета и нажимаем «Сохранить». Результат будет записан на жесткий диск.Важно!
Пакет содержит много файлов. Чтобы не вносить путаницу, пишите его в отдельную папку. Не сохраняйте пакет в каталог, где уже хранятся какие-то данные.
РаспознаеМ документ
Структура таблицы определена, и можно распознавать документ. Делаем так:
1) первым делом на панели инструментов проверяем
язык распознавания. На рис. 2 таким языком является «Украинский». Чтобы изменить его, щелчком мыши раскрываем список и выбираем подходящий вариант;2) нажимаем «
Ctrl+R», чтобы распознать текущую страницу документа. Можно воспользоваться меню «Процесс → Распознать → Распознать». Чтобы распознать все страницы, нажмите «Ctrl+Shift+R» или вызовите меню «Процесс → Распознать → Распознать все».Результат распознавания FineReader покажет в окне «
Текст» (рис. 2). Если FineReader что-то сделал не так, корректируем разметку и заново распознаем страницу.Совет
При повторном распознавании можно ограничиться только теми страницами, в которые были внесены изменения. Для этого выделяем их и нажимаем «Ctrl+R».
ПЕРЕДАЕМ РЕЗУЛЬТАТ В MS OFFICE
Чтобы сохранить текущую страницу в Word или Excel, сделайте так:
1) на панели инструментов найдите иконку с номером «
4». Над ней будет написано название программы. Это может быть «Microsoft Word», «Microsoft Excel», «Microsoft PowerPoint», «StarWriter», «Web-браузер», «Буфер обмена» или «Adobe Acrobat/Reader». Скорей всего, вам понадобится «Microsoft Word» или «Microsoft Excel»;2) если надпись на кнопке соответствует нужной программе, просто щелкните на ней. Через некоторое время появится окно с выбранным приложением, в которое FineReader поместит результат.
Есть и другие способы импортирования данных во внешнее приложение. Щелкаем на значке раскрытия списка кнопки с номером «
4» (рис. 2). FineReader предложит пять способов работы: «Мастер сохранения результатов», «Сохранить страницы…», «Передать страницы в…», «Передать все страницы в…» и «Опции…» (рис. 8 на с. 23). На практике можно ограничиться двумя вариантами: «Передать страницы в…» и «Передать все страницы в…». Они отличаются только тем, что в первом случае импортируется текущая или выделенные страницы. Во втором случае FineReader передаст во внешнее приложение все страницы документа. Оба меню содержат несколько разделов. Их количество зависит от состава установленных программ на вашем компьютере. Можно смело ограничить свой выбор тремя: «Microsoft Word», «Microsoft Excel» и «Буфер обмена». Выберите любой из указанных пунктов. FineReader вызовет указанное приложение и передаст в него результат распознавания.
Пример
Завершая тему, вернемся к документу на рис. 1 и пройдем по всем этапам распознавания этой сложной таблицы. Моя попытка распознать его в автоматическом режиме успехом не увенчалась. Таблица не простая, оригинал был не лучшего качества, и в конечном итоге получилась каша. Привести в порядок результат распознавания оказалось сложнее, чем создать бланк «с нуля». Так как большинство ошибок были связаны с неправильным определением структуры таблицы, пришлось выполнить разметку таблицы вручную. Делаем так:
1. Нажимаем «
Ctrl+Shift+T» (меню «Изображение → Исправить разрешение…». Появится окно «Исправить разрешение», как на рис. 5 на с. 21.2. В окне выбираем вариант «
Отсканированное изображение (300 dpi)». Нажимаем «ОК».3. Щелкаем на инструменте «
Выделить блок Таблица». Обводим весь документ.4. Внутри созданного блока щелкаем правой кнопкой мыши. Из контекстного меню выбираем «
Анализ структуры таблицы». FineReader поставит линии разметки ячеек в автоматическом режиме.5. После разметки выяснилось, что объединенная ячейка «
Обсяги поставки (база оподаткування)…» разделена на четыре колонки. Ячейка «Надано Покупцю» в четвертом разделе налоговой накладной разделена на две строки, а в оригинале это объединенная ячейка. В строке «Усього по розділу I» FineReader неверно распознал сумму «34,25». Причина в том, что в левом верхнем углу этой ячейки есть треугольный маркер, который FineReader принял за текст. Исправим эти ошибки.6. Выделяем ячейки с текстом «
Надано» и «Покупцю».7. Щелкаем правой кнопкой мыши. Из контекстного меню выбираем «
Ячейки таблицы → Объединить ячейки».8. Выделяем по горизонтали четыре ячейки с текстом «
Обсяги поставки (база оподаткування)…».9. Щелкаем правой кнопкой мыши. Из контекстного меню выбираем «
Ячейки таблицы → Объединить ячейки».10. Выбираем инструмент «
Ластик» (рис. 2). Указатель мыши примет форму квадрата.11. Увеличиваем масштаб окна
Изображение».12. Ставим указатель мыши внутрь ячейки с числом «
34,25» (строка «Усього по розділу I»). Указатель должен находиться справа от числа, но не закрывать его!13. Удерживая левую кнопку мыши, обводим блок в направлении «влево и вверх». Наша цель — аккуратно обвести участок изображения с дефектом в углу ячейки (рис. 1). Граница ячейки в область блока попадать не должна!
14. Отпускаем кнопку мыши. FineReader удалил треугольник с изображения.
15. Нажимаем «
Ctrl+R», чтобы распознать текущую страницу.16. Щелкаем на значке раскрывающего списка у иконки «
Сохранить».17. Из появившегося меню выбираем «
Передать страницы в → Microsoft Excel».18. В Excel появится бланк с документом «
Налоговая накладная».Думаю, на этом можно закрыть вопрос по распознаванию таблиц. Надеюсь, что эта статья поможет решить такую задачу быстро и без проблем.
Жду ваших вопросов, писем, предложений и замечаний на
bk@id.factor.ua или на форуме редакции www.bk.factor.ua/forum . Успешной работы!


