

Як розпізнати таблицю
Шановна редакціє! Мені час від часу доводиться сканувати, а потім розпізнавати друковані документи. Здебільшого це різні бланки, форми звітності тощо. Використовую FineReader 8.0. Оскільки користуюся я цією програмою недавно, досвіду роботи з нею мало. Мабуть, тому часто виникають проблеми при розпізнаванні таблиць. Особливо, коли текст надрукований дрібним шрифтом і оригінал невисокої якості (середній ксерокс). Підкажіть, як правильно обробляти таблиці? Може, знайдеться декілька порад? Заздалегідь дякую.
Юлія Савіна, м. Харків
Відповідає Тамара КРАВЧЕНКО, консультант «Б & К»
Сканування та розпізнавання документів — процес специфічний. Це не означає, що він складний і підвладний тільки професіоналу. Нічого подібного. Проблема полягає в іншому. Бухгалтер звик оперувати текстом, числами, діаграмами. Тут він почувається, як риба у воді. Але як тільки мова заходить про розпізнавання документа, хоч-не-хоч доводиться звертатися до елементів комп'ютерної графіки. Для бухгалтера це середовище незвичне, підводні камені йому малознайомі. Через це і виникають прикрі помилки, які роблять процес розпізнавання тривалим та (що найобразливіше!) малоефективним. Хоча насправді все дуже просто: потрібно виконати декілька умов, і більшість проблем зникнуть. Адже сучасні програми розпізнавання (OCR-програми) мають чудові алгоритми вирішення завдання. Якщо користуватися ними вміло, то свою роботу вони виконають блискуче. Неважливо, обробляєте ви текст чи таблицю! Тому, відповідаючи на запитання, ми повинні з'ясувати чотири моменти:
— що можна розпізнавати і чого розпізнавати не варто;
— на що звернути увагу при підготовці документа до розпізнавання (у тому числі табличного);
— як швидко розпізнати та відкоригувати документ;
— як зберегти документ та передати його до офісної програми.
За цим планом і побудуємо відповідь, акцентуючи увагу на розпізнаванні основних бухгалтерських об’єктів — таблиць.
Процес розпізнавання…
Докладно про процес розпізнавання ми писали у статті «Як розпізнати... документ» (див. «Б & К», 2008, № 9 — 10). Отже, не повторюватимемося, нагадаємо тільки найголовніше. Розпізнавання — це переведення графічного файлу у формат текстового документа або електронної таблиці. Його використовують, щоб отримати електронну версію документа з друкованого оригіналу. Для виконання такої роботи є спеціальні програми. Наприклад, система оптичного розпізнавання FineReader. Вихідним матеріалом для неї є відскановане (сфотографоване) зображення. Програма FineReader аналізує його, намагаючись знайти фрагменти зі «смисловим» змістом (текст, таблиці, рисунки). Інакше кажучи, вона визначає структуру документа, виділяє зі знеособленого зображення літери, слова, речення за їх зовнішнім виглядом. Потім, спираючись на цю інформацію, FineReader формує текстовий (або табличний) документ, перевіряє його за системою словників та пропонує користувачу для остаточного контролю. Коли перевірку завершено, результат роботи можна передати в текстовий процесор Word або таблицю Excel. І там уже з документом можна робити все, що завгодно.
Процес розпізнавання багатокроковий, він складається з таких етапів:
1) сканування документа (отримання його зображення);
2) передача його до програми розпізнавання (завантаження одного чи декількох зображень);
3) обробка зображення: очищення від сміття, поворот, усунення перекручень тощо;
4) розмітка зображення. Тут вказують, як FineReader повинен обробити ті чи інші фрагменти рисунка, — що вважати таблицею, що інтерпретувати як звичайний текст тощо. Це — важливий етап роботи, від нього залежить якість кінцевого результату;
5) розпізнавання розміченого зображення;
6) перегляд результатів роботи, коригування помилок розпізнавання;
7) перетворення результатів у формат Word або Excel.
Подивимося, як усе це зробити на практиці.
… і його реалізація в FineReader
Як приклад відразу беремо табличний документ, наприклад, фрагмент податкової накладної (рис. 1). У цьому документі є всі характерні риси бухгалтерського бланка: складна шапка, об’єднання рядків та колонок, обернений текст. Документ отримано копіюванням екрана за комбінацією клавіш «
Alt+Print Screen».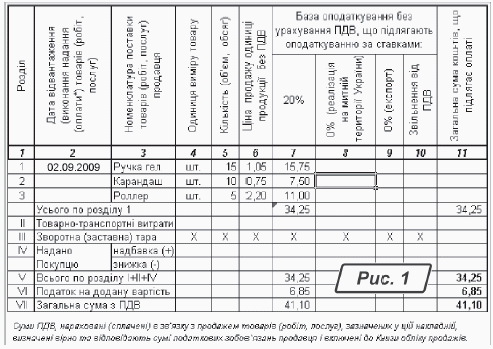
Важливо!
Для хорошого розпізнавання зображення має бути розділенням порядку 300 dpi та за розмірами відповідати оригіналу. У нас ця умова не виконується, оскільки копія екрана має розділення в межах від 76 dpi до 120 dpi (докладніше про характеристики зображень розповідалося у статті «Бухгалтеру — про графіку» («Б & К», 2007, № 10). На одному з етапів ми відкоригуємо розділення прямо у програмі FineReader.Викликаємо FineReader. Можна скористатися ознайомлювальною версією 8.0, скачавши її з
http://www.abbyy.ru/Download/ . З’явиться вікно, як на рис. 2 на с. 20. У верхній його частині є п’ять іконок: «Scan&Read», «Открыть», «Распознать», «Проверить», «MicroSoft Excel». Вони повністю відстежують описану послідовність дій з розпізнавання документа. Не вистачає тільки пунктів з коригування зображення. Але вони є і знаходяться в текстовому меню. Основну частину вікна розбито на чотири частини. Ліворуч розташована область сторінок. Кожна сторінка — це окреме зображення. Праворуч від області сторінок є віконце «Изображение». У ньому видно фрагмент відсканованого документа, а також його розмітку . У правій частині вікна показано результат розпізнавання. Це — текстовий документ. Його можна правити прямо у програмі FineReader. Унизу розташована область зі збільшеною копією зображення. Між областю сторінок та вікном «Изображение» є робоче меню для розмітки рисунка перед його розпізнаванням. Структура інтерфейсу, думаю, зрозуміла. Розпочнемо розпізнавання таблиці.
ЗАВАНТАЖУЄМО ДОКУМЕНТ
Файл з нашим прикладом знаходиться на жорсткому диску. Спочатку потрібно прочитати його у програму FineReader. Для цього робимо так:
1) натискуємо «
Ctrl+O» або викликаємо меню «Файл → Открыть PDF/Изображение»;2) з’явиться вікно «
Проводника». У ньому знаходимо папку, виділяємо потрібні файли, клацаємо по кнопці «Открыть» або натискуємо «Enter». Завантажені зображення з’являться в області сторінок.Для завантаження документа зі сканера призначено кнопку «
Scan&Read». Ось як нею користуватися:1) вмикаємо сканер, кладемо до нього документ;
2) натискуємо «
Scan&Read». З’явиться вікно управління сканером. Наповнення цього вікна залежить від конкретної моделі пристрою. Але в будь-якому разі тут можна вибрати тип зображення (чорно-біле або кольорове) та його розділення;3) визначивши параметри сканування, натискуємо «
ОК». Залишається тільки дочекатися результату.
КОРИГУЄМО ЗОБРАЖЕННЯ
Таблицю завантажено в FineReader. Насамперед потрібно з’ясувати, чи не потребує графічний документ додаткової обробки. Таку обробку можна виконати через меню «
Изображение» (рис. 3 на с. 20). Ось основні можливості цього меню у плані коригування зображень.
«
Повернуть/Отразить изображение». У цьому меню п’ять пунктів (рис. 4 на с. 21). Їх використовують, коли сторінку відскановано з поворотом та її необхідно переорієнтовувати (текст повинен розміщатися в напрямі «зверху вниз» та «зліва направо»). У нас таблиця орієнтована правильно. Розділ « Повернуть/Отразить изображение» пропускаємо. 
«Исправить разрешение…». Тут можна змінити розділення вихідного зображення. Нам така можливість потрібна. Тому робимо так:
1) натискуємо «Ctrl+Shift+T» (або входимо в меню «Изображение → Исправить разрешение…»;
2) з’явиться вікно, як на рис. 5. Вибираємо варіант «Отсканированное изображение (300 dpi)»;

3) переходимо до перемикача «Исправить разрешение». Він визначає зону дії інструменту та приймає одне із двох значень: «Выбранных изображений» або «Всех изображений пакета». У нас завантажено один рисунок. Тому перемикач у групі «Исправить разрешение» можна встановити довільно. Залишаємо «Выбранных изображений». FineReader змінить розділення вибраних зображень;
4) натискуємо «ОК».
«
Обработать изображение». У цьому розділі зосереджені інструменти для поліпшення якості картинки.Важливо!
Серйозні дефекти зображення FineReader не усуне. Але трохи «почистити» його, видалити дрібні погрішності, смітинки, плямочки він зможе.У меню зібрано чотири пункти: «
Устранить искажение строк», «Инвертировать», «Очистить изображение от мусора», «Очистить блок от мусора ». Вони мають таке призначення:— «
Устранить искажение строк», прибирає один із поширених дефектів сканування, коли деякі рядки тексту розташовані під кутом один до одного. Є й інші приклади. Скажімо, коли при скануванні книги краї рядків біля палітурки спрямовані не точно по прямій, а злегка «округлено» (через вигин аркушів). Щоб виправити ситуацію, робимо так:1) виділяємо одну або декілька сторінок документа;
2) викликаємо меню «
Изображение → Обработать изображение → Устранить искажение строк». Рядки буде вирівняно. Ця операція дуже важлива при роботі з таблицями.Порада
Не застосовуйте вирівнювання рядків відразу до всього документа. Обробляйте сторінки по одній, кожного разу переглядаючи результат своїх дій;— «
Инвертировать», змінює кольори та яскравості зображення на протилежні;— «
Очистить изображение от мусора» та «Очистить блок от мусора», видаляють із зображення дрібні дефекти (сліди пилу, подряпини тощо).
РОЗМІЧАЄМО ТАБЛИЦЮ
Це — найважливіший етап роботи з розпізнавання документа. Сенс його такий. Інформація в документі буває трьох видів: текст, таблиця та рисунок. Програмі FineReader потрібно точно «знати», з чим вона має справу. Тому на першому ж етапі розпізнавання FineReader ділить зображення на ділянки та намагається з’ясувати, що в них записано. Для простих документів проблем зазвичай не виникає. Але при обробці сторінок зі складним форматуванням FineReader може помилитися. Причому такі помилки найчастіше виникають при обробці таблиць.
Порада
При роботі з таблицями при обробці сторінок з версткою в декілька колонок та великою кількістю рисунків розмічайте документ уручну.Опанувати прийоми ручної розмітки сторінок зовсім не складно. Усі інструменти для такої роботи зосереджено на спеціальній панелі. Вона знаходиться ліворуч від області сторінок. Почнемо з іконки з літерою «
Т»: це інструмент для визначення текстового блока. Нижче йдуть іконки «Выделить блок Таблица» та «Выделить блок Картинка». Ми збираємося розпізнавати таблицю. Отже, нам потрібно виділити на сторінці блок типу «Таблица». Робимо так:1) клацаємо лівою кнопкою миші на іконці «
Выделить блок Таблица»;2) ставимо покажчик на
зображенні документа, де починається таблиця;3) утримуючи ліву кнопку миші, обводимо блок. Робимо це акуратно. Зайвий простір краще не захоплювати, але зовнішня межа таблиці має повністю знаходитися усередині блока;
4) відпускаємо кнопку миші. На документі з’явилася прямокутна область синього кольору. Вона повинна охоплювати фрагмент зображення, який FineReader розглядатиме як таблицю. Якщо це не так, змініть розмір блока. Для цього виділяємо блок та розтягуємо його за кут або межу так само, як ви змінюєте розмір вікна в системі Windows. Щоб видалити блок розмітки, виділяємо його та натискуємо клавішу «
Del».Отже, блок із таблицею виділено. Раджу відразу ж розпізнати її
структуру. Робимо так:1) виділяємо блок типу «
Таблица», клацаємо по ньому правою кнопкою миші;2) із контекстного меню вибираємо «
Анализ структуры таблицы». На зображенні з’явиться сітка з вертикальних та горизонтальних ліній. В ідеалі вони повинні лягти точно на межі елементів вихідної таблиці;3) перевіряємо результат. Наше завдання — переконатися, що FineReader правильно розпізнав усі елементи таблиці. Для цього послідовно клацаємо лівою кнопкою миші по клітках табличної частини документа. Виділену комірку буде забарвлено синім кольором. Звіряємо її місце розташування з оригіналом. Якщо при розмітці таблиці є помилки, їх доведеться виправити вручну.
ПРАВИМО РОЗМІТКУ ТАБЛИЦІ
Якщо оригінали невисокої якості, FineReader може помилитися вже при виділенні блоків у вихідному зображенні. Така проблема часто виникає при роботі з таблицями. Наприклад, FineReader може пропустити дуже бліду лінію межі та об’єднати декілька комірок в одну. Або, навпаки, розділити комірку там, де цього робити не потрібно. У будь-якому разі розмітку документа доведеться відкоригувати самому. Для цього на панелі розмітки блоків передбачено спеціальні кнопки: «
Добавить вертикальную линию», «Добавить горизонтальную линию» та «Удалить линии». Користуватися ними дуже просто:1) клацніть по іконці «
Добавить вертикальную линию»;2) перемістіть покажчик миші у вікно «
Изображение». Разом з покажчиком переміщатиметься передбачувана лінія розмітки;3) поставте її на потрібне місце, клацніть лівою кнопкою миші. Лінію буде зафіксовано, але інструмент продовжує працювати! Додайте решту ліній, яких не вистачає в розмітці таблиці;
4) виберіть інструмент «
Добавить горизонтальную линию». За такою самою схемою створіть горизонтальні лінії розмітки;5) щоб завершити роботу в режимі додавання ліній, виберіть інший інструмент розмітки.
Може виявитися, що при розпізнаванні структури таблиці FineReader запровадив у документ зайві лінії розмітки. Щоб видалити їх, робіть так:
1) клацніть лівою кнопкою на інструменті «
Удалить линии» (рис. 2);2) поставте покажчик миші в область «
Изображение» на лінію, яку маєте намір видалити;3) коли покажчик набуде форми хрестика, клацніть лівою кнопкою миші — лінія зникне;
4) щоб закінчити роботу з іконкою «
Удалить линии», виберіть інший інструмент розмітки.У бухгалтерських бланках часто-густо зустрічаються
об’єднані комірки. Причому як за рядками, так і за колонками. За моїми спостереженнями, саме в таких випадках FineReader допускає найбільше помилок. Причини можуть бути різними. Наприклад, дуже тонкий папір оригіналу. І сканер, і фотоапарат — оптичні пристрої з високою чутливістю. При скануванні документа на тонкому папері вони можуть «побачити» рядки, розташовані зі зворотного боку аркуша. Текст цих рядків FineReader не розпізнає. А от прийняти ледь помітні тіні за бліді лінії меж він може. І тому розмітку таблиці зробить неправильно, додавши зайві рядки. Найчастіше ця помилка виявляється на об’єднаних комірках, як показано на рис. 6. На оригіналі комірка «Надано Покупцю» у четвертому розділі податкової накладної об’єднана на два рядки по вертикалі. Але FineReader помітив ледь помітну горизонтальну тінь та розділив комірку на два рядки. У верхній залишив «Надано», а до нижньої помістив текст «Покупцю». Видалення зайвої лінії розмітки в цьому випадку не допоможе. Адже і справа, і зліва від цієї комірки лінії повинні залишитися! Тому застосуємо об’єднання комірок. Робимо так: 
1) виділяємо декілька комірок по вертикалі або горизонталі;
2) клацаємо по виділенню правою кнопкою миші. З’явиться контекстне меню, як на рис. 7;

3) вибираємо пункт «Ячейки таблицы → Объединить ячейки» (або викликаємо меню «Изображение → Ячейки таблицы → Объединить ячейки»).
Щоб розділити об’єднану комірку по вертикалі або горизонталі, зробіть так:
1) поставте покажчик усередину комірки;
2) клацніть правою кнопкою миші;
3) із контекстного меню виберіть пункт «Ячейки таблицы → Разбить ячейки».
Порада
Перш ніж розпізнавати таблицю, чітко визначте її структуру. Якщо потрібно, уручну розставте лінії розмітки, об’єднайте та розділіть комірки. Причому все це робіть у програмі FineReader.І ось чому. Так чи інакше при коригуванні розпізнаного документа вам знадобиться порівнювати його з оригіналом. Для цього вам доведеться в одному вікні відкрити Word або Excel з документом, в іншому — графічне зображення. І потім постійно перемикати вікна, порівнюючи оригінал та результат розпізнавання. У програмі FineReader жодних перемикань робити не потрібно. І оригінал, і результат розпізнавання, і збільшену копію зображення видно в одному вікні! Більше того, FineReader підтримує синхронне переміщення покажчика по розпізнаному документу та його графічному зображенню. У такому режимі коригувати документ набагато зручніше.
ЗБЕРІГАЄМО РЕЗУЛЬТАТ
Робота з розпізнавання великого документа може тривати довго. Образливо витратити чимало часу на створення блоків, правку документа та потім усе втратити. Звичайно, результат потрібно періодично зберігати. Для цього в FineReader використовується поняття «пакет». Пакет об’єднує в собі вихідні зображення, їх розмітку та результат розпізнавання в тому вигляді, якими вони були на момент його створення. Зберегти пакет можна через меню «
Файл → Сохранить пакет как…». З’явиться вікно Провідника. У ньому вибираємо папку, уводимо назву пакета та натискуємо «Сохранить». Результат буде записано на жорсткий диск.Важливо!
Пакет містить багато файлів. Щоб не вносити плутанину, записуйте його в окрему папку. Не зберігайте пакет у каталог, де вже зберігаються якісь дані.
РОЗПІЗНАЄМО ДОКУМЕНТ
Структуру таблиці визначено. Можна розпізнавати документ. Робимо так:
1) насамперед на панелі інструментів перевіряємо мову розпізнавання. На рис. 2 такою мовою є «
Украинский». Щоб змінити її, клацанням миші розкриваємо список та вибираємо відповідний варіант;2) натискуємо «
Ctrl+R», щоб розпізнати поточну сторінку документа. Можна скористатися меню «Процесс → Распознать → Распознать». Щоб розпізнати всі сторінки, натисніть «Ctrl+Shift+R» або викличте меню «Процесс → Распознать → Распознать все».Результат розпізнавання FineReader покаже у вікні «
Текст» (рис. 2). Якщо FineReader щось зробив не так, коригуємо розмітку та заново розпізнаємо сторінку.Порада
При повторному розпізнаванні можна обмежитися тільки тими сторінками, куди було внесено зміни. Для цього виділяємо їх та натискуємо «Ctrl+R».
ПЕРЕДАЄМО РЕЗУЛЬТАТ до MS OFFICE
Щоб зберегти поточну сторінку в Word або Excel, робіть так:
1) на панелі інструментів знайдіть іконку з номером «
4». На ній буде написано назву програми. Це може бути «Microsoft Word», «Microsoft Excel», «Microsoft PowerPoint», «StarWriter», «Web-браузер», «Буфер обмена» або «Adobe Acrobat/Reader». Найімовірніше, вам знадобиться «Microsoft Word» або «Microsoft Excel»;2) якщо напис на кнопці відповідає потрібній програмі, просто клацніть по ній. Через деякий час з’явиться вікно з вибраним додатком, до якого FineReader помістить результат.
Є й інші способи імпортування даних у зовнішній додаток. Клацаємо по значку розкриття списку кнопки з номером «
4» (рис. 2). FineReader запропонує п’ять способів роботи: «Мастер сохранения результатов», «Сохранить страницы…», «Передать страницы в…», «Передать все страницы в…», «Опции…» (рис. 8 на с. 23). На практиці можна обмежитися двома варіантами: «Передать страницы в…» та «Передать все страницы в…». Вони відрізняються тільки тим, що в першому випадку імпортується поточна або виділені сторінки. У другому випадку FineReader передасть у зовнішній додаток усі сторінки документа. Обидва меню містять декілька розділів. Їх кількість залежить від складу встановлених програм на вашому комп’ютері. Можна сміливо обмежити свій вибір трьома: «Microsoft Word», «Microsoft Excel» та «Буфер обмена». Виберіть будь-який із зазначених пунктів. FineReader викличе зазначений додаток та передасть до нього результат розпізнавання. 
Приклад
Завершуючи тему, повернемося до документа на рис. 1 та пройдемо за всіма етапами розпізнавання цієї складної таблиці. Моя спроба розпізнати його в автоматичному режимі успіху не мала. Таблиця не проста, оригінал був не дуже якісним, зрештою вийшло казна-що. Привести в порядок результат розпізнавання виявилося складнішим, ніж створити бланк «з нуля». Оскільки більшість помилок було пов'язано з неправильним визначенням структури таблиці, довелося виконати розмітку таблиці вручну. Робимо так:
1) натискуємо «
Ctrl+Shift+T» (меню «Изображение → Исправить разрешение…». З’явиться вікно «Исправить разрешение» (рис. 5 на с. 21));2) у ньому вибираємо варіант «
Отсканированное изображение (300 dpi)». Натискуємо «ОК»;3) клацаємо по інструменту «
Выделить блок Таблица». Обводимо весь документ;4) усередині створеного блока клацаємо правою кнопкою миші. З контекстного меню вибираємо «
Анализ структуры таблицы». FineReader поставить лінії розмітки комірок в автоматичному режимі;5) після розмітки з’ясувалося, що об’єднана комірка «
Обсяги поставки (база оподаткування)…» розділена на чотири колонки. Комірка «Надано Покупцю» у четвертому розділі податкової накладної розділена на два рядки. А в оригіналі це — об’єднана комірка. У рядку «Усього по розділу I» FineReader неправильно розпізнав суму «34,25». Причина в тому, що в лівому верхньому кутку цієї комірки є трикутний маркер, який FineReader прийняв за текст. Виправимо ці помилки;6) виділяємо комірки з текстом «
Надано» та «Покупцю»;7) клацаємо правою кнопкою миші. З контекстного меню вибираємо «
Ячейки таблицы → Объединить ячейки»;8) виділяємо по горизонталі чотири комірки з текстом «
Обсяги поставки (база оподаткування)…»;9) клацаємо правою кнопкою миші. Із контекстного меню вибираємо «
Ячейки таблицы → Объединить ячейки»;10) вибираємо інструмент «
Ластик» (рис. 2). Покажчик миші набуде форму квадрата;11) збільшуємо масштаб вікна «
Изображение»;12) ставимо покажчик миші всередину комірки з числом «
34,25» (рядок «Усього по розділу I»). Покажчик має знаходитися праворуч від числа, але не закривати його;13) утримуючи ліву кнопку миші, обводимо блок у напрямі «вліво та вгору». Наша мета — акуратно обвести ділянку зображення з дефектом у кутку комірки (рис. 1). Межа комірки в область блоку потрапляти не повинна;
14) відпускаємо кнопку миші. FineReader видалив трикутник із зображення;
15) натискуємо «
Ctrl+R», щоб розпізнати поточну сторінку;16) клацаємо по значку, що розкриває список в іконці «
Сохранить»;17) із меню, що з’явилося, вибираємо «
Передать страницы в → Microsoft Excel»;18) в Excel з’явиться бланк з документом «
Налоговая накладная».Вважаю, на цьому можна закрити питання щодо розпізнавання таблиць. Сподіваюся, що ця стаття допоможе вирішити таке завдання швидко і без проблем.
Чекаю ваших запитань, листів, пропозицій та зауважень на
bk@id.factor.ua або на форумі редакції www.bk.factor.ua/forum . Успішної роботи!


